A Large Language Model (LLM) is a type of AI system that can generate human-like text. It does this by learning from large datasets (e.g. books, articles, websites, etc.) and using that knowledge to predict the next word in a sequence.
LLMs are now used across a wide range of applications and tasks, like support chatbots, copywriting, translation, summarization, search, and code generation. As an engineer, understanding how LLMs work can help you integrate AI features into your web applications and speed up your development workflow.
LLMs are built on a type of neural network called a transformer, which is especially good at understanding context.
While LLMs are complex systems with different implementations, they follow a general process:
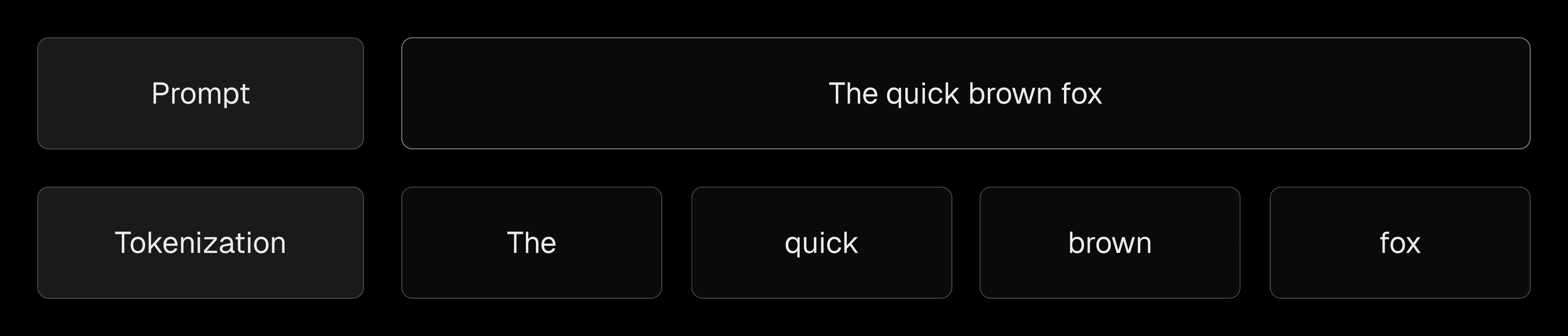
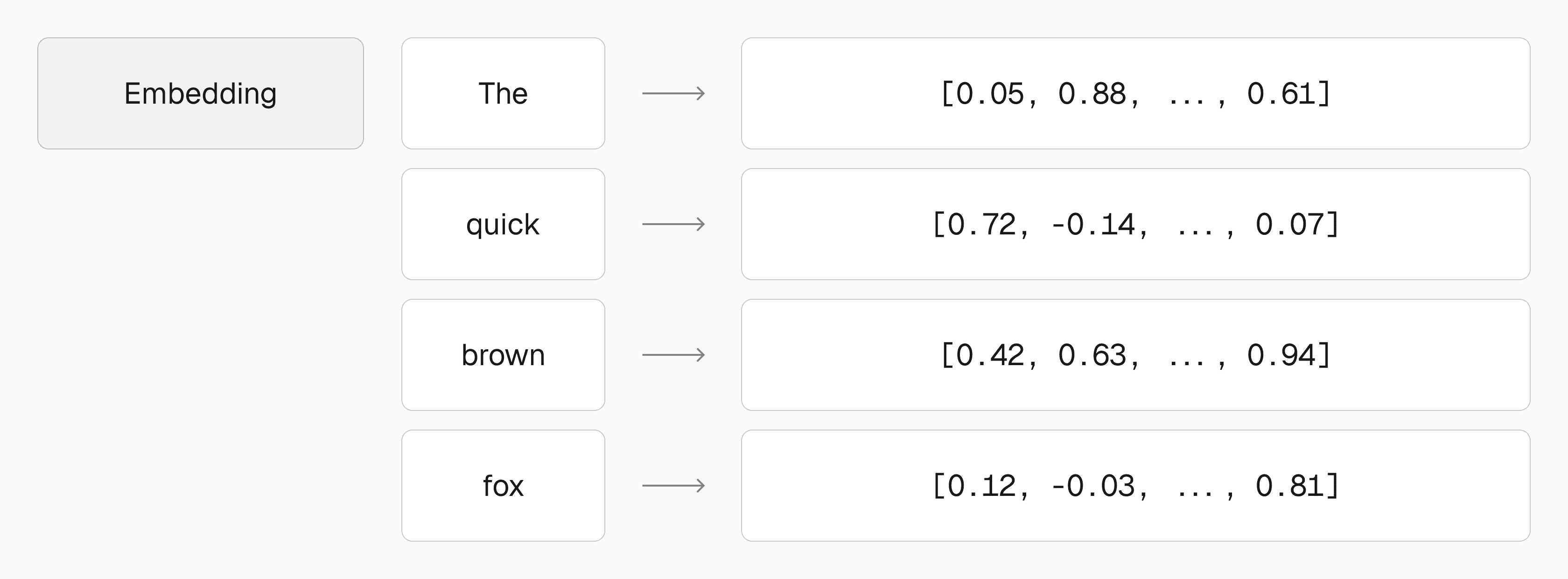
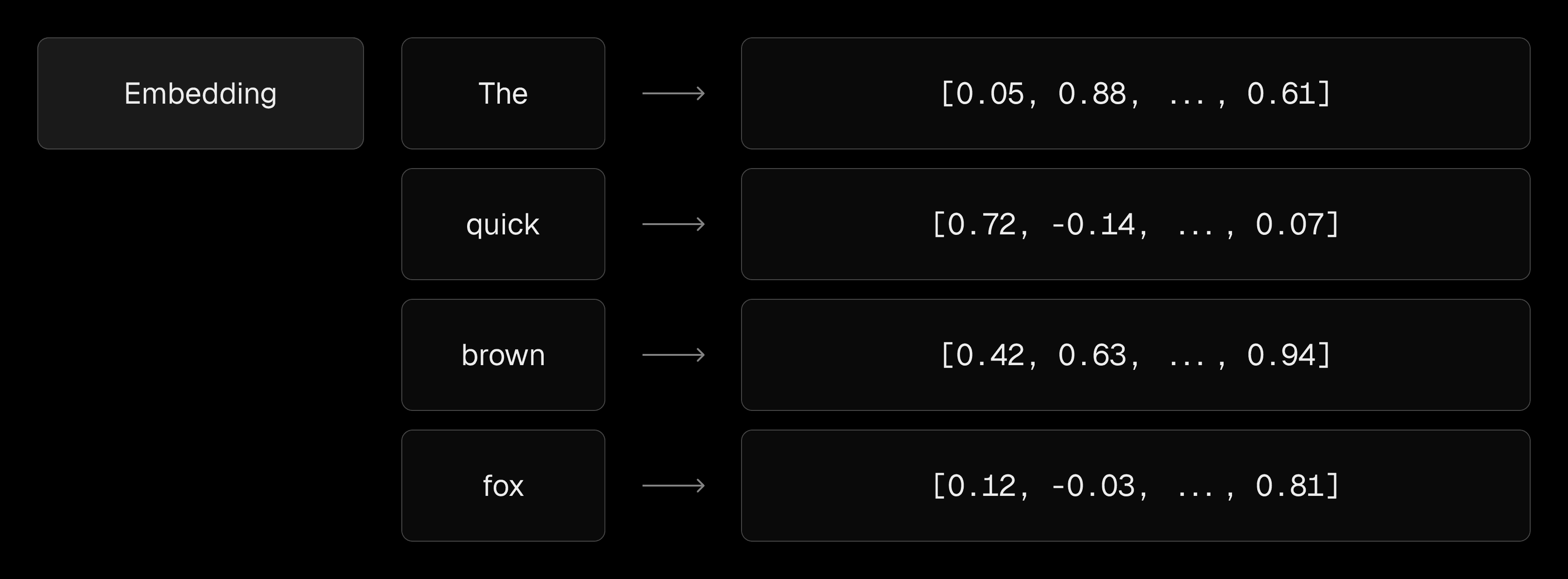
Before training, text is broken down into tokens, that is, small units like words or subwords (e.g. Hello World! → ["Hello", "World", "!"]). These are then embedded (converted into vectors) so the model can process them.
The model processes hundreds of billions of these tokens, learning to predict the next one in each sequence. Over time, it adjusts its internal parameters (called "weights") to improve these predictions.
Once trained, you give it a prompt (a natural language input), and it predicts the most likely sequence of tokens based on what it has learned. Try it out:
Some models are further fine-tuned on domain-specific data to improve quality of responses for particular use cases.
For example, v0 is trained on frontend libraries and documentation to help it generate accurate UI code from natural language prompts like "add a pricing section" or "create a login form". Try it out:
After training, some models are further refined using human feedback. Humans rank model outputs, and those preferences are used to adjust the model's responses to be more helpful.
When you send a prompt to an LLM:
Your prompt is tokenized into smaller units.

Each token is embedded as a high-dimensional vector.
These vectors pass through multiple transformer layers, which apply attention to weigh the importance of each token in context.
The model predicts the next token in the sequence, repeating the whole process for each token until a complete response is generated.


The final response is then decoded back into human-readable text.


LLMs don't retrieve answers, they generate them using context and probability. That's what makes them flexible and powerful.
LLMs can support your development workflow in a number of ways. Here are some common use cases:
LLMs can be integrated into your own applications to build AI features. Most models are available via API, allowing you to query them just as you would a backend service. For example:
You can use LLMs to generate code and UI from natural language, reducing the time spent on routine tasks. For example:
Boilerplate: Reduce time spent setting up new projects and configuring tooling.
Prototype: Create POCs to validate ideas before building.
Logic: Generate code to solve specific problems.
LLMs reduce the "grunt work", allowing engineers to spend more time focusing on higher-level coding tasks while becoming the curators of quality.
LLMs can help diagnose errors, explain stack traces, and suggest potential fixes based on context. They're useful for narrowing down causes of bugs. For example:
Review code and recommend fixes:
You can also use LLMs within your code editor to act as your "pair programmer". Popular AI-powered IDEs include Cursor, GitHub Copilot in VSCode, and more.
LLMs can explain unfamiliar concepts, summarize documentation, or answer questions about tools and frameworks. This makes them useful for onboarding or exploring new APIs. For example:
Explaining concepts:
Learning new tools:
Here are a few widely used LLMs:
Start building AI features by integrating LLMs into your application: