There is a long-standing myth that serverless compute inherently requires more connections to traditional databases. The real issue is not the number of connections needed during normal operation, but that some serverless platforms can leak connections when functions are suspended.
In this post, we show why this belief is incorrect, explain the actual cause of the problem, and provide a straightforward, simple-to-use solution.
Link to headingYou can stop reading now if
Your application uses a modern, stateless protocol like HTTP for database connections (for example, DynamoDB, Fauna, or Firestore)
You use a connection pooler with such a high maximum connection count that it's effectively unlimited and exhaustion is not a practical concern (for example, AWS RDS Proxy; Google Cloud SQL Auth Proxy and Azure Flexible Server offer similar capabilities, although experiences may vary)
For everybody else:
Link to headingThe ground truth
If your application uses a database connection pool (e.g., Postgres, MySQL, Oracle, MSSQL, Redis), the number of concurrent database connections you need is determined solely by the number of concurrent requests you process. This is true for every compute model:
Single large server (threaded or multi-process)
Many small servers behind a load balancer
Serverless instances such as AWS Lambda or Vercel Fluid
Event loop models with non-blocking IO
Without pooling, unpredictable traffic can quickly exhaust available connections in any of these. With pooling, the math works out the same across all models.
For example, processing 1,000 concurrent requests requires 1,000 active pool clients:
Traditional database connections are non-concurrent, so best practice is still one pool client per in-flight request. This is why the total connections are identical across compute models.
So, if all compute models are the same, is there actually anything special with respect to serverless and database connection pool?
Link to headingThe real problem
There is something unique about serverless and connection pools, but it is not about the steady-state number of connections. The real problem comes from the lifecycle of the underlying virtual machines in a serverless system.


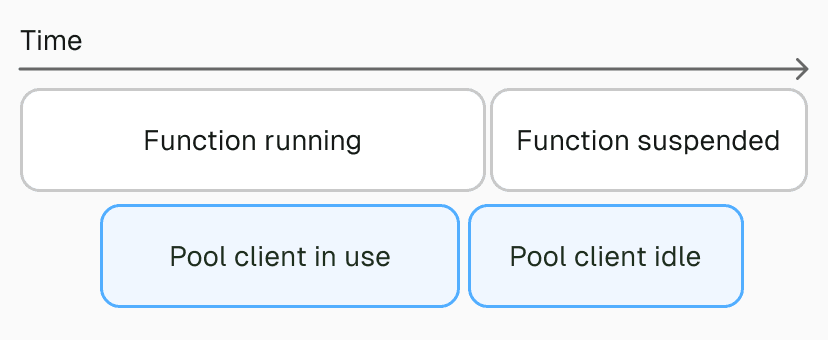
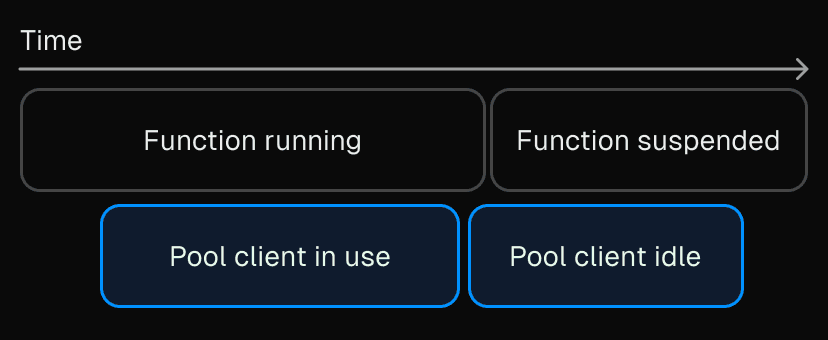
In a serverful environment, machines and VMs typically go through three phases:
Provisioning (getting ready)
Serving traffic (where most time is spent)
Deprovisioning (removed from service, releasing all pool clients)
In a traditional serverless environment, the lifecycle is different:
Provision or start up
Serve traffic
Suspend when idle, remaining in memory but not executing until another request arrives
Eventually delete the suspended VM without a clean shutdown
Step 4 might sound like the problem, but it is not serious. When the VM is deleted, its sockets to the database pool are closed, and the pool will reclaim those connections.
Step 3 is the real issue.
Link to headingWhy suspension leaks connections
Database connections exist in two states:
Active: currently executing a query
Idle: available for reuse, awaiting another request
When a client becomes idle, a timer in the pool should eventually close it if no new request arrives. If the function is suspended, this timer never fires. As a result, the connection remains open until either:
The instance is shut down (Step 4 above)
The server-side pooler closes the connection due to its own timeout
Both events usually take minutes. During that time, the connection is effectively leaked.
Link to headingSo, is this a real problem?
You really only need to worry about this issue if you are constrained on max connections on your database pooler. This is definitely a thing in the real world. E.g. on Supabase’s free plan, the maximum number of concurrent connections to the pooler is 200. At 200, leaking, say 50 of them, can really hurt.
And unfortunately the “leaks” can be heavily correlated. E.g. if you deploy a new version of your app, 100% of your old serverless functions will both suspend and never get traffic again. All of these functions will leak their connection pools until they time out on the pooler-side.
Link to headingIs there a solution?
In traditional serverless environments such as AWS Lambda, there is no practical solution without trade-offs. Closing the database connection after every request would stop leaks but introduce significant latency, since every request would need to open a new connection.
In modern serverless platforms like Vercel Fluid Compute, the issue of the leaked connections can be solved. Fluid supports a feature called waitUntil, which allows a function to remain alive just long enough to complete work after the main request finishes. This can be used to close idle connections before suspension.
Algorithm:
When a client is released back to the pool, schedule a timer slightly longer than the idle timeout
Use
waitUntilto keep the function alive until the timer fires and closes the clientIf another client is released before the timer fires, cancel and reschedule the timer
With this implemented, the Fluid Compute model closes pool clients exactly the same as any serverful solution. Problem solved.
In practice, you do not have to implement this yourself. In Fluid Compute, one line after pool configuration handles it:
import { Pool } from "pg";import { attachDatabasePool } from "@vercel/functions"
const pool = new Pool({ connectionString: process.env.POSTGRES_URL,});attachDatabasePool(pool);That’s it. Connection leak issue solved.
Read the full documentation on database connection pool management to see how it works in detail.
Link to headingCost implications
Keeping a function alive slightly longer has a cost, but with Active CPU Pricing for Fluid compute, the impact is close to zero:
While the function is alive, it can still process new requests. Only the very last request that would have leaked a connection adds extra time
Waiting for the idle timer consumes no CPU time, so you only pay the small memory reservation cost
Link to headingBest practices
Link to headingConfigure relatively low connection idle timeouts
You control the idle timeout for your database connection pool. If connections are limited, it makes sense to set this to a relatively low value, such as 5 seconds. This provides good reuse when your service is busy and ensures idle connections are released quickly when traffic is low.
Link to headingDefine your connection pools globally
In every compute model, define your database connection pools in a global scope so they can be shared between requests. This is the core purpose of a connection pool and avoids creating unnecessary new connections.
Link to headingDon’t set the maximum pool size to 1
There is bad advice on the internet that recommends setting the maximum pool size to 1 for AWS Lambda. This does not reduce total connections, as Lambda will not make more connections anyway, and it can still leak that single connection.
While a small maximum does not harm Lambda specifically, it is harmful for Fluid Compute and serverful models because it prevents them from taking advantage of concurrent execution.
In most cases, the minimum pool size should remain at 1, which is typically the default. Increasing this value is rarely useful except for specific workloads that are extremely "bursty", where the time between bursts is longer than your idle timeout.
Link to headingUtilize rolling releases
Rolling releases in Vercel gradually shift traffic from one deployment to the next. This avoids a single “thundering herd” of new services coming online and connecting to the database.
Deployments systems such as Kubernetes with rolling updates provide similar features.
If you are on Fluid Compute, also use attachDatabasePool as described above to ensure idle connections are closed before suspension.
Link to headingSummary
Serverless compute does not require a larger number of database pool clients during normal operation. The real problem is leaking connections when serverless functions are suspended.
In traditional serverless compute, there is no known solution for this issue that avoids significant trade-offs. Modern serverless solutions such as Fluid Compute provide lifecycle hooks that allow connections to be released properly, preventing leaks with minimal additional cost and no impact on latency.